Implementing a RAG tool
In this hands-on tutorial, we'll build a powerful WebRAGTool that can fetch and process web content dynamically, enhancing your AI agents' ability to provide accurate and contextually relevant responses.
Our documentation is available in an LLM-friendly format at docs.kaibanjs.com/llms-full.txt. Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
We will be using:
- KaibanJS: For Agents Orchestration.
- LangChain: For the WebRAGTool Creation.
- OpenAI: For LLM inference and Embeddings.
- React: For the UI.
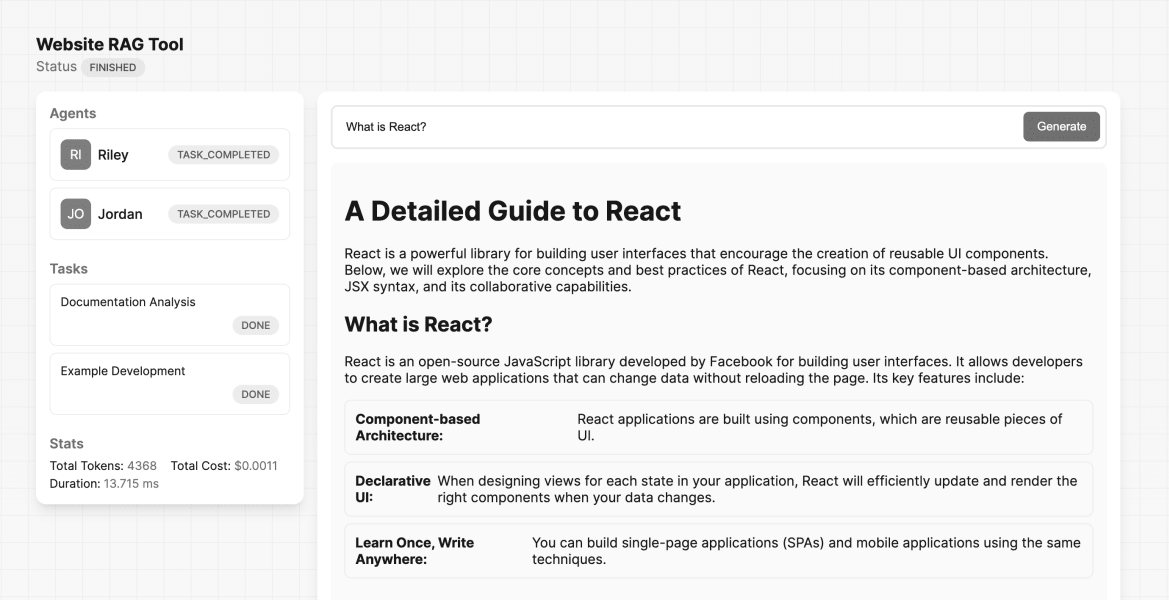
Final Result
A basic React App that uses the WebRAGTool to answer questions about the React documentation website.
Ready to dive straight into the code? You can find the complete project on CodeSandbox by following the link below:
View the completed project on a CodeSandbox
Feel free to explore the project and return to this tutorial for a detailed walkthrough!
Parts of the Tutorial
This tutorial assumes you have a basic understanding of the KaibanJS framework and custom tool creation. If you're new to these topics, we recommend reviewing the following resources before proceeding:
These guides will provide you with the foundational knowledge needed to make the most of this tutorial.
On this tutorial we will:
-
Explain Key Components of a RAG Tool: A RAG (Retrieval Augmented Generation) tool typically consists of several key components that work together to enhance the capabilities of language models. Understanding these components is crucial before we dive into building our WebRAGTool.
-
Create a WebRAGTool: The Tool will fetch content from specified web pages. Processes and indexes this content. Uses the indexed content to answer queries with context-specific information.
-
Test the WebRAGTool: We'll create a simple test to verify that the WebRAGTool works as expected.
-
Integrate the WebRAGTool into your KaibanJS Environment: We'll create AI agents that utilize the WebRAGTool.These agents will be organized into a KaibanJS team, demonstrating multi-agent collaboration.
-
Create a simple UI: We will point you to an existing example project that uses React to create a simple UI for interacting with the WebRAGTool.
Let's Get Started.
Key Components of a RAG Tool
Before we start building the WebRAGTool, let's understand the key components that make it work:
| Component | Description | Example/Usage in Tutorial |
|---|---|---|
| Source | Where information is obtained for processing and storage. Your knowledge base. PDFs, Web PAges, Excell, API, etc. | Web pages (HTML content) |
| Vector Storage | Specialized database for storing and retrieving high-dimensional vectors representing semantic content | In-memory storage |
| Operation Type | How we interact with vector storage and source | Write: Indexing web content - Read: Querying for answers |
| LLM (Large Language Model) | AI model that processes natural language and generates responses | gpt-4o-mini |
| Embedder | Converts text into vector representations capturing semantic meaning | OpenAIEmbeddings |
By combining these components, our WebRAGTool will be able to:
- fetch web content,
- convert it into searchable vector form.
- store it efficiently.
- use it to generate informed responses to user queries.
Now that we've covered the key components of our RAG system, let's dive into the implementation steps.
Create a WebRAGTool
1. Setting Up the Environment
First, let's install the necessary dependencies and set up our project:
npm install kaibanjs @langchain/core @langchain/community @langchain/openai zod cheerio
Now, create a new file called WebRAGTool.js and add the following imports and class structure:
import { Tool } from '@langchain/core/tools';
import 'cheerio';
import { CheerioWebBaseLoader } from '@langchain/community/document_loaders/web/cheerio';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import { OpenAIEmbeddings, ChatOpenAI } from '@langchain/openai';
import { createStuffDocumentsChain } from 'langchain/chains/combine_documents';
import { StringOutputParser } from '@langchain/core/output_parsers';
import { MemoryVectorStore } from 'langchain/vectorstores/memory';
import { ChatPromptTemplate } from '@langchain/core/prompts';
import { z } from 'zod';
export class WebRAGTool extends Tool {
constructor(fields) {
super(fields);
this.url = fields.url;
this.name = 'web_rag';
this.description = 'This tool implements Retrieval Augmented Generation (RAG) by dynamically fetching and processing web content from a specified URL to answer user queries.';
this.schema = z.object({
query: z.string().describe('The query for which to retrieve and generate answers.'),
});
}
async _call(input) {
try {
// Create Source Loader Here
// Implement Vector Storage Here
// Configure LLM and Embedder Here
// Build RAG Pipeline Here
// Generate and Return Response Here
} catch (error) {
console.error('Error running the WebRAGTool:', error);
throw error;
}
}
}
This boilerplate sets up the basic structure of our WebRAGTool class. We've included placeholders for each major component we'll be implementing in the subsequent steps. This approach provides a clear roadmap for what we'll be building and where each piece fits into the overall structure.
2. Creating the Source Loader
In this step, we set up the source loader to fetch and process web content. We use CheerioWebBaseLoader to load HTML content from the specified URL, and then split it into manageable chunks using RecursiveCharacterTextSplitter. This splitting helps in processing large documents while maintaining context.
Replace the "Create Source Loader Here" comment with the following code:
// Create Source Loader Here
const loader = new CheerioWebBaseLoader(this.url);
const docs = await loader.load();
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits = await textSplitter.splitDocuments(docs);
3. Implementing the Vector Storage
Here, we create a vector store to efficiently store and retrieve our document chunks. We use MemoryVectorStore for in-memory storage and OpenAIEmbeddings to convert our text chunks into vector representations. This allows for semantic search and retrieval of relevant information.
Replace the "Implement Vector Storage Here" comment with:
// Implement Vector Storage Here
const vectorStore = await MemoryVectorStore.fromDocuments(
splits,
new OpenAIEmbeddings({
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
})
);
const retriever = vectorStore.asRetriever();
4. Configuring the LLM and Embedder
In this step, we initialize the language model (LLM) that will generate responses based on the retrieved information. We're using OpenAI's ChatGPT model here. Note that the embedder was already configured in the vector store creation step.
Replace the "Configure LLM and Embedder Here" comment with:
// Configure LLM and Embedder Here
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
});
5. Building the RAG Pipeline
Now we create the RAG (Retrieval-Augmented Generation) pipeline. This involves setting up a prompt template to structure input for the language model and creating a chain that combines the LLM, prompt, and document processing.
Replace the "Build RAG Pipeline Here" comment with:
// Build RAG Pipeline Here
const prompt = ChatPromptTemplate.fromTemplate(`
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:`);
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
});
6. Generate and Return Response
Finally, we use our RAG pipeline to generate a response. This involves retrieving relevant documents based on the input query and then using the RAG chain to generate a response that combines the query with the retrieved context.
Replace the "Generate and Return Response Here" comment with:
// Generate and Return Response Here
const retrievedDocs = await retriever.invoke(input.query);
const response = await ragChain.invoke({
question: input.query,
context: retrievedDocs,
});
return response;
Complete WebRAGTool Implementation
After following the detailed step-by-step explanation and building each part of the WebRAGTool, here is the complete code for the tool. You can use this to verify your implementation or as a quick start to copy and paste into your project:
import { Tool } from '@langchain/core/tools';
import 'cheerio';
import { CheerioWebBaseLoader } from '@langchain/community/document_loaders/web/cheerio';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import { OpenAIEmbeddings, ChatOpenAI } from '@langchain/openai';
import { createStuffDocumentsChain } from 'langchain/chains/combine_documents';
import { StringOutputParser } from '@langchain/core/output_parsers';
import { MemoryVectorStore } from 'langchain/vectorstores/memory';
import { ChatPromptTemplate } from '@langchain/core/prompts';
import { z } from 'zod';
export class WebRAGTool extends Tool {
constructor(fields) {
super(fields);
// Store the URL from which to fetch content
this.url = fields.url;
// Define the tool's name and description
this.name = 'web_rag';
this.description =
'This tool implements Retrieval Augmented Generation (RAG) by dynamically fetching and processing web content from a specified URL to answer user queries. It leverages external web sources to provide enriched responses that go beyond static datasets, making it ideal for applications needing up-to-date information or context-specific data. To use this tool effectively, specify the target URL and query parameters, and it will retrieve relevant documents to generate concise, informed responses based on the latest content available online';
// Define the schema for the input query using Zod for validation
this.schema = z.object({
query: z
.string()
.describe('The query for which to retrieve and generate answers.'),
});
}
async _call(input) {
try {
// Step 1: Load Content from the Specified URL
const loader = new CheerioWebBaseLoader(this.url);
const docs = await loader.load();
// Step 2: Split the Loaded Documents into Chunks
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits = await textSplitter.splitDocuments(docs);
// Step 3: Create a Vector Store from the Document Chunks
const vectorStore = await MemoryVectorStore.fromDocuments(
splits,
new OpenAIEmbeddings({
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
})
);
// Step 4: Initialize a Retriever
const retriever = vectorStore.asRetriever();
// Step 5: Define the Prompt Template for the Language Model
const prompt = ChatPromptTemplate.fromTemplate(`
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:`);
// Step 6: Initialize the Language Model (LLM)
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
});
// Step 7: Create the RAG Chain
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
});
// Step 8: Retrieve Relevant Documents Based on the User's Query
const retrievedDocs = await retriever.invoke(input.query);
// Step 9: Generate the Final Response
const response = await ragChain.invoke({
question: input.query,
context: retrievedDocs,
});
// Step 10: Return the Generated Response
return response;
} catch (error) {
// Log and rethrow any errors that occur during the process
console.error('Error running the WebRAGTool:', error);
throw error;
}
}
}
This complete code snippet is ready to be integrated into your project. It encompasses all the functionality discussed in the tutorial, from fetching and processing data to generating responses based on the retrieved information.
Testing the WebRAGTool
Once you have implemented the WebRAGTool, testing it is crucial to ensure it functions as intended. Below is a step-by-step guide on how to set up and run a simple test. This test mimics a realistic use-case, similar to how an agent might invoke the tool within the KaibanJS framework once it is integrated into an AI team.
First, ensure that you have the tool script in your project. Here’s how you import the WebRAGTool that you've developed:
import { WebRAGTool } from './WebRAGTool'; // Adjust the path as necessary
Next, define a function to test the tool by executing a query through the RAG process:
async function testTool() {
// Create an instance of the WebRAGTool with a specific URL
const tool = new WebRAGTool({
url: 'https://react.dev/',
});
// Invoke the tool with a query and log the output
const queryResponse = await tool.invoke({ query: "What is React?" });
console.log(queryResponse);
}
testTool();
Example Console Output:
React is a JavaScript library for building user interfaces using components, allowing developers to create dynamic web applications. It emphasizes the reuse of components to build complex UIs in a structured manner. Additionally, React fosters a large community, enabling collaboration and support among developers and designers.
The console output provided is an example of the potential result when using RAG to enhance query responses. It illustrates the tool's capability to provide detailed and context-specific information, which is critical for building more knowledgeable and responsive AI systems. Remember, the actual output may vary depending on updates to the source content and modifications in the processing logic of your tool.
Integrating the WebRAGTool into Your KaibanJS Environment
Once you have developed the WebRAGTool, integrating it into your KaibanJS environment involves a few key steps that link the tool to an agent capable of utilizing its capabilities. This integration ensures that your AI agents can effectively use the RAG functionality to enhance their responses based on the latest web content.
Step 1: Import the Tool
First, ensure the tool is accessible within your project by importing it where you plan to use it:
import { WebRAGTool } from './WebRAGTool'; // Adjust the path as necessary based on your project structure
Step 2: Initialize the Tool
Create an instance of the WebRAGTool, specifying the URL of the data source you want the tool to retrieve information from. This URL should point to the web content relevant to your agent's queries:
const webRAGTool = new WebRAGTool({
url: 'https://react.dev/' // Specify the URL to fetch content from, tailored to your agent's needs
});
Step 3: Assign the Tool to an Agent
With the tool initialized, the next step is to assign it to an agent. This involves creating an agent and configuring it to use this tool as part of its resources to answer queries. Here, we configure an agent whose role is to analyze and summarize documentation:
import { Agent, Task, Team } from 'kaibanjs';
const docAnalystAgent = new Agent({
name: 'Riley',
role: 'Documentation Analyst',
goal: 'Analyze and summarize key sections of React documentation',
background: 'Expert in software development and technical documentation',
tools: [webRAGTool] // Assign the WebRAGTool to this agent
});
By following these steps, you seamlessly integrate RAG into your KaibanJS application, enabling your agents to utilize dynamically retrieved web content to answer queries more effectively. This setup not only makes your agents more intelligent and responsive but also ensures that they can handle queries with the most current data available, enhancing user interaction and satisfaction.
Step 4: Integrate the Team into a Real Application
After setting up your individual agents and their respective tools, the next step is to combine them into a team that can be integrated into a real-world application. This demonstrates how different agents with specialized skills can work together to achieve complex tasks.
Here's how you can define a team of agents using the KaibanJS framework and prepare it for integration into an application:
import { Agent, Task, Team } from 'kaibanjs';
import { WebRAGTool } from './tool';
const webRAGTool = new WebRAGTool({
url: 'https://react.dev/',
});
// Define the Documentation Analyst Agent
const docAnalystAgent = new Agent({
name: 'Riley',
role: 'Documentation Analyst',
goal: 'Analyze and summarize key sections of React documentation',
background: 'Expert in software development and technical documentation',
tools: [webRAGTool], // Include the WebRAGTool in the agent's tools
});
// Define the Developer Advocate Agent
const devAdvocateAgent = new Agent({
name: 'Jordan',
role: 'Developer Advocate',
goal: 'Provide detailed examples and best practices based on the summarized documentation',
background: 'Skilled in advocating and teaching React technologies',
tools: [],
});
// Define Tasks
const analysisTask = new Task({
title: 'Documentation Analysis',
description: 'Analyze the React documentation sections related to {topic}',
expectedOutput: 'A summary of key features and updates in the React documentation on the given topic',
agent: docAnalystAgent,
});
const exampleTask = new Task({
title: 'Example Development',
description: 'Provide a detailed explanation of the analyzed documentation',
expectedOutput: 'A detailed guide with examples and best practices in Markdown format',
agent: devAdvocateAgent,
});
// Create the Team
const reactDevTeam = new Team({
name: 'AI React Development Team',
agents: [docAnalystAgent, devAdvocateAgent],
tasks: [analysisTask, exampleTask],
env: { OPENAI_API_KEY: import.meta.env.VITE_OPENAI_API_KEY }
});
export { reactDevTeam };
Using the Team in an Application:
Now that you have configured your team, you can integrate it into an application. This setup allows the team to handle complex queries about React, processing them through the specialized agents to provide comprehensive answers and resources.
For a practical demonstration, revisit the interactive example we discussed earlier in the tutorial:
View the example project on CodeSandbox
This link leads to the full project setup where you can see the team in action. You can run queries, observe how the agents perform their tasks, and get a feel for the interplay of different components within a real application.
Conclusion
By following this tutorial, you've learned how to create a custom RAG tool that fetches and processes web content, enhancing your AI's ability to provide accurate and contextually relevant responses.
This comprehensive guide should give you a thorough understanding of building and integrating a RAG tool in your AI applications. If you have any questions or need further clarification on any step, feel free to ask!
Acknowledgments
Thanks to @Valdozzz for suggesting this valuable addition. Your contributions help drive innovation within our community!
Feedback
Is there something unclear or quirky in this tutorial? Have a suggestion or spotted an issue? Help us improve by submitting an issue on GitHub. Your input is valuable!